Фэйкавыя дыпломы і геаметка па фота: як тэхналогіі абводзяць нас вакол пальца?
- Рубрыка: MEDIASCAPE
- 04.06.2025
- 2315
Пакуль мы гартаем мемы, загружаем у інсту фоткі з адпачынку або праходзім чарговы тэст «Якую знакамітасць ты нагадваеш?», штучны інтэлект пільна сочыць: аналізуе мову, запыты, звычкі. Запамінае, як мы выглядаем, дзе любім бавіць час, з кім найчасцей перапісваемся і што гатуем на сняданак. ШI вучыцца штодня і становіцца ўсё больш дасканалым. Зразумела, што яго дасканаласць служыць добрую службу не толькі нам. У гэтым матэрыяле мы сабралі некалькі свежых кейсаў, якія маглі б быць пакладзеныя ў сцэнары «Black Mirror», але гэта не фантазіі пра будучыню, а рэальнасць, якая ўжо надышла.
Падробка «пруфаў» у некалькі клікаў
Вясной у сетцы X з’явіўся ўражлівы трэд пра здольнасці нейрасеткі падрабляць дакументы так, што ад сапраўдных з першага погляду і не адрозніш. Болей за тое, у ШІ-падробак, створаных усяго за некалькі секунд, ёсць вялікі шанец прайсці аўтаматычныя сістэмы верыфікацыі. «Большасць сістэм праверкі, якія просяць “проста даслаць фота”, афіцыйна састарэлі», – канстатуе God of Prompt і публікуе 7 пруфаў: фэйкавыя ліст авіякампаніі аб адмене рэйса, адмену падпіскі, скрыншот мабільнага банкінгу, дыплом, медыцынскі рэцэпт, картку страхавання аўтамабіля і нават працоўную візу.
Усё падроблена досыць дэталёва: напрыклад, рэцэпт выглядае нібыта сфатаграфаная на тэлефон у хатніх умовах паперчына, на якой ад рукі напісана назначэнне лекара. Страхавыя кампаніі і працадаўцы часта прымаюць фота ў якасці пацверджання запытаў, і больш глыбокая праверка адбываецца толькі ў выпадках, калі ўзнікаюць падазрэнні. Зразумела, што падробка візы ці дыплома, хутчэй за ўсё, прывядзе да праблем з законам, але шмат дзе чалавек пройдзе першы этап адбору, а глыбокай праверкі, магчыма, і не адбудзецца або яна будзе фармальная. Так на нашых вачах нейрасеткі ператвараюцца са шчырых памочнікаў у хаўруснікаў махляроў.

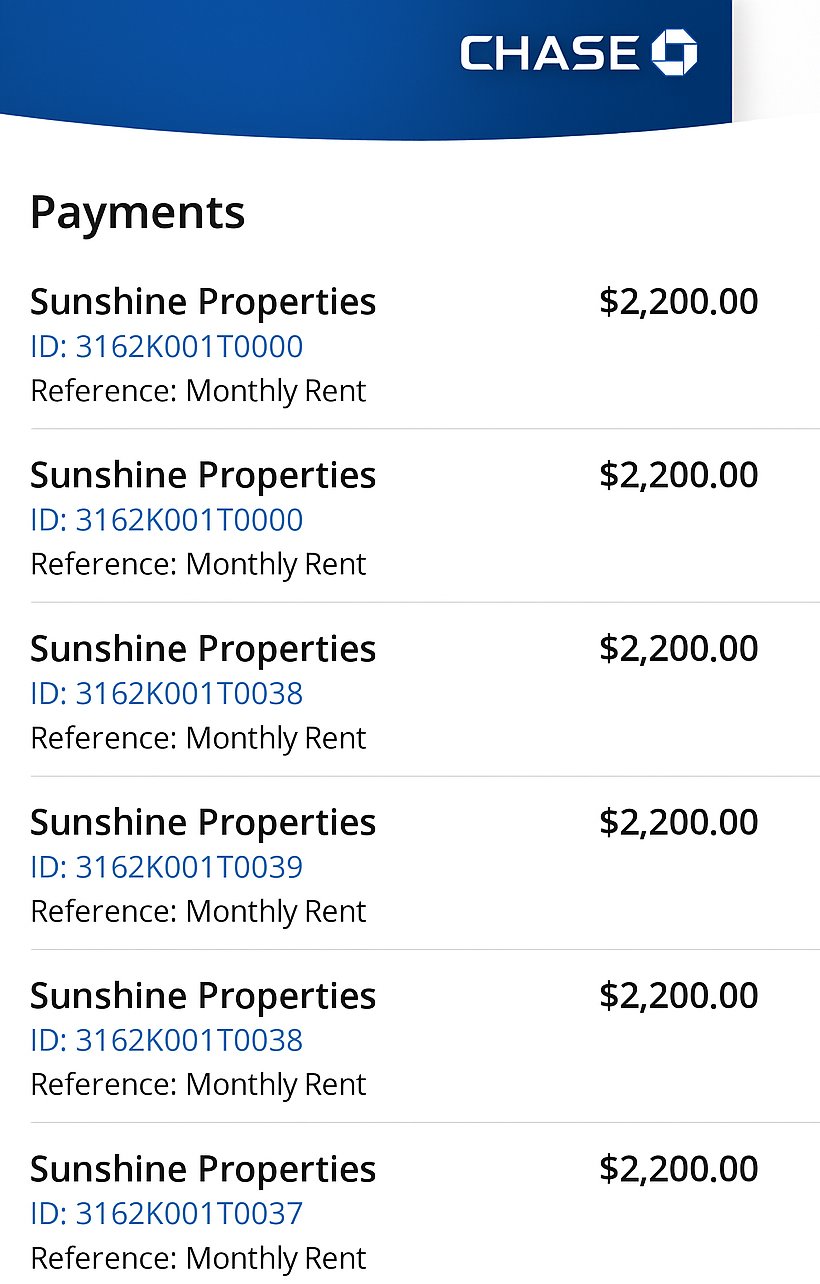
Чэк і выпіска з банкінгу, падробленыя ШІ
Вядома, OpenAI маркіруе выявы спецыяльнымі метаданымі, але, каб іх убачыць, патрэбныя спецыфічныя інструменты. Да таго ж дасведчаныя карыстальнікі здольныя гэтыя меткі выдаляць. І пакуль сістэмы кантролю не паспяваюць за тэхналогіямі, варта трымаць у галаве прыказку «давярай, але правярай» і перад прыняццем важных рашэнняў сур’ёзна падыходзіць да праверкі любых докаў.
Вызначэнне лакацыі па здымках
У красавіку OpenAI прадставіла новыя мадэлі ШІ o3 і o4-mini, здольныя вельмі глыбока аналізаваць прадастаўленыя ім фотаздымкі. Нейронкі могуць разабраць фота амаль на малекулы, знайсці падказкі, за якія можна зачапіцца, і, карыстаючыся пошукам у інтэрнэце, вызначыць, дзе менавіта быў зроблены фотаздымак. То-бок можна нешта сфоткаць з адключанай геалакацыяй, але ШІ прааналізуе будынкі, цені, расліны, тэкстуры на заднім плане – і адшукае пункт на мапе.
З назіранняў карыстальнікаў атрымліваецца, што OpenAI не карыстаецца для пошуку лакацыі гісторыяй дыялогаў з ChatGPT (выдыхаем!) і нават не выцягвае інфу з метададзеных фота. Аднак праблема з канфідэнцыяльнасцю відавочная. Можна «скарміць» чату чужое сэлфі з кавярні – і атрымаць дакладную геаметку. Можна прапанаваць ШІ ўявіць, нібыта ён гуляе ў GeoGuessr (анлайн-гульню, дзе трэба ўгадваць месцы па здымках Google Street View), – і вуаля!
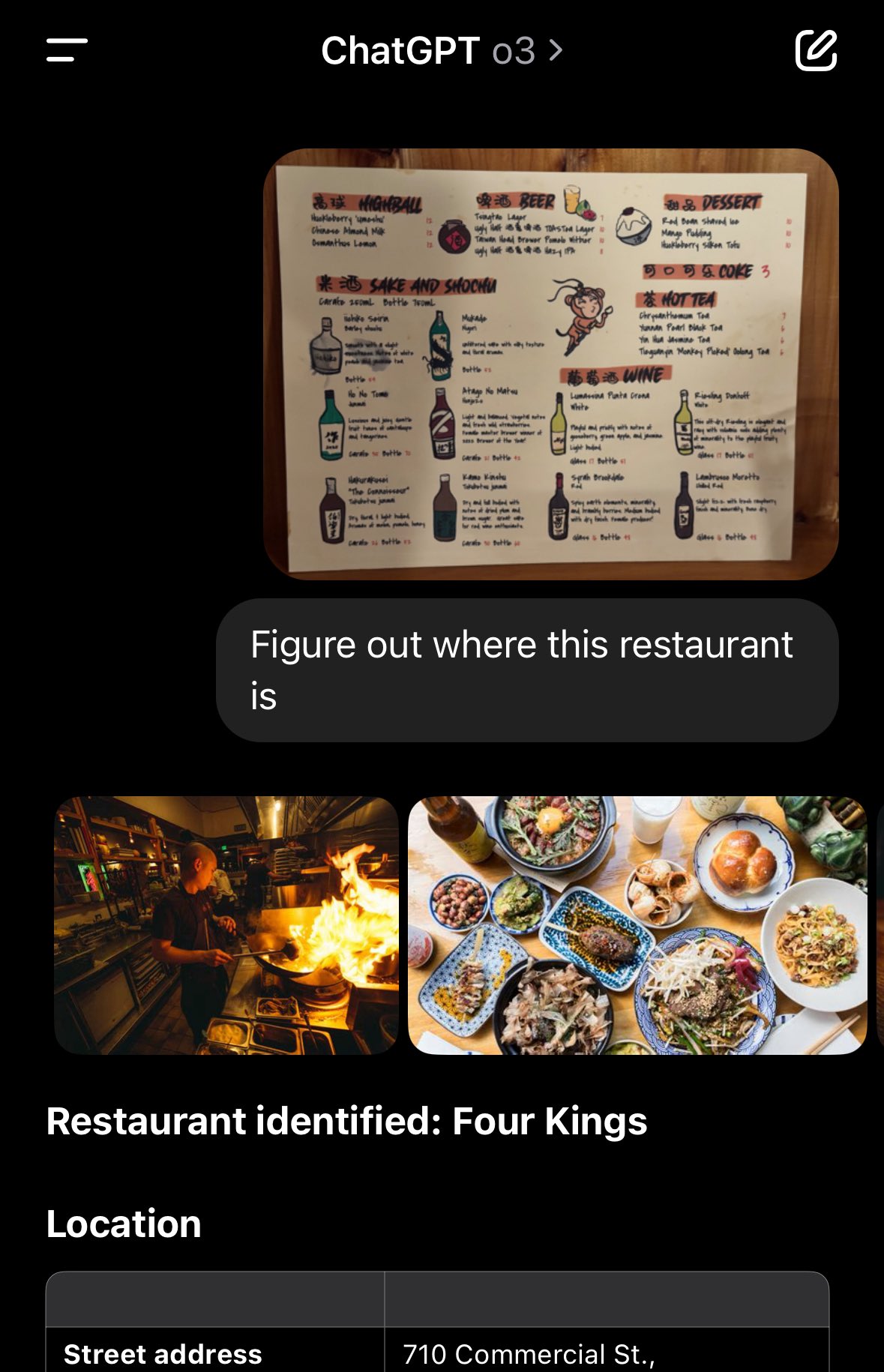
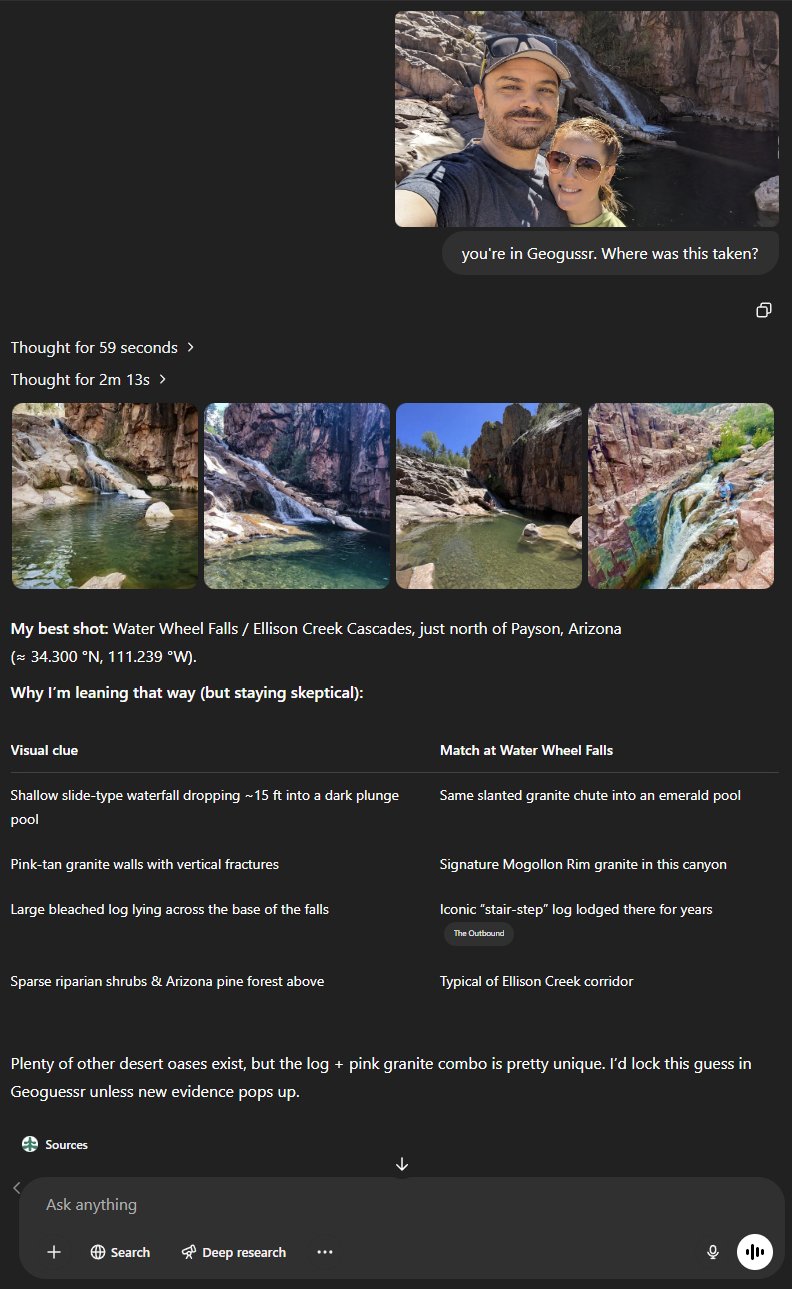
ШІ менш чым за хвіліну вызначае, дзе быў зроблены фотаздымак
Вядома, не любое фота дазволіць атрымаць геалакацыю, а часам замест таго, каб прызнацца ў няведанні, ШІ заяўляе памылковую лакацыю, і ён можа трапляць зусім «у малако». Але абараніцца ад пошуку лакацыі з фота ў ChatGPT немагчыма, а яго стваральнікі ўвогуле не лічаць такія звышздольнасці машыны праблемай для карыстальнікаў.
Навучанне машын на персанальных пастах
У красавіку кампанія Meta (уладальнік Instagram і Facebook) афіцыйна абвясціла, што будзе выкарыстоўваць публічныя пасты, каментары і гісторыі карыстальнікаў з Еўрасаюза для навучання сваіх ШІ-мадэляў (амерыканскія і брытанскія юзары даўно «на алоўку»). Такім чынам, відэа з канцэрта ці фота з падарожжа могуць трапіць у навучальныя базы нейрасетак, каб тыя стваралі больш натуральныя галасы, выявы, а таксама лепш разумелі гумар і дыялектныя выразы.
Раней, нагадаем, Meta прапанавала жыхарам Еўропы карыстацца ШІ-ботам непасрэдна ў апках WhatsApp, Facebook, Instagram і Messenger. Гэта можа быць карысна і зручна, але, калі ў цябе няма жадання ўдзельнічаць у навучанні штучнага інтэлекту сваімі асабістымі дадзенымі, ты можаш закрыць некаторыя доступы ў наладах прыватнасці (добрая нагода яшчэ раз чэкнуць, якія ў цябе зараз дамоўленасці з Meta).
Без кастынгу – у галоўнай ролі
На фоне выбуховага росту дыпфэйкаў – фальшывых відэа, дзе кожны можа нечакана «засвяціцца» ў ролі, якую ніколі не граў, – YouTube летась увёў магчымасць скардзіцца на відэа з выкарыстаннем твараў або галасоў людзей без іх ведама. І на платформе, сапраўды, паменшала рэкламы «ад Ілана Маска». Аднак галоўная праблема ў тым, што публікацыі з менш пазнавальнымі тварамі могуць жыць у сетцы тыднямі, пакуль карыстальнік(-ца) выпадкова не знойдзе свой твар у публікацыі або не даведаецца пра існаванне дыпфэйка ад знаёмых.
Адзін з самых вядомых дыпфэйкаў, дзе «Барак Абама» называе Трампа «поўным прыдуркам»
Таму лепш не спяшацца выкладаць свае фота на сайты кшталту «Каго са знакамітасцяў ты нагадваеш?». Падобныя платформы цалкам могуць збіраць карцінкі для нейкіх сваіх патаемных мэтаў. А гарантый, што твой брэдпітаўскі ці анджалінаджольны твар не ўсплыве недзе ў іншым месцы, ніхто не дасць.
Неасабістае асабістае
Карыстанне чатамі накшталт GPT стала часткай штодзённага жыцця. Яны падтрымліваюць, падказваюць, дапамагаюць сфармуляваць думку або напісаць тэрміновы мэйл у рэлевантным стылі. Але як разумее межы канфідэнцыйнасці тая ці іншая праграма – звычайна акрэслена не тое каб празрыста. Так, нядаўна высветлілася, што кітайскі DeepSeek, які наступаў на пяткі амерыканскаму ChatGPT і нават апярэджваў яго па колькасці пампаванняў, абыходзіў сістэмныя абмежаванні і перадаваў дадзеныя карыстальнікаў без іх ведама. Праграма захоўвала паролі без шыфравання, перадавала інфармацыю ў Кітай на серверы ByteDance (афіліяваная з TikTok кампанія) і мела доступ да персанальных дадзеных, якія не павінна была збіраць увогуле.
Амерыканская кампанія NowSecure заклікала да поўнай забароны DeepSeek – прынамсі ў дзяржаўным сектары. Пакуль жа глабальныя правілы не распрацаваныя, і як праверыць добрасумленнасць чата, пачынаючы ім карыстацца, – вялікае пытанне.
Хто можа ведаць пра твае месячныя?
Мільёны жанчын па ўсім свеце карыстаюцца для адсочвання менструальнага цыклу папулярным і зручным дадаткам Flo, распрацаваным беларусамі. Сёлета кампанію абвінавацілі ў продажы тэхнагігантам дадзеных аб менструацыях, сэксуальнай актыўнасці і планах на цяжарнасць. У позве сцвярджаецца, што асабістую інфармацыю карыстальніц атрымлівалі Google, Meta і аналітычная платформа Flurry.
Федэральная гандлёвая камісія ЗША выдала Flo папярэджанне, Flurry заплаціла штраф у 3,5 млн даляраў, а калектыўная позва ўсё яшчэ разглядаецца. Цяпер дадатак мусіць удасканаліць дамову на збор дадзеных карыстальніц і праводзіць рэгулярны аўдыт. Але пытанне даверу застаецца адкрытым – тым больш што гэта не першая такая гісторыя з Flo.
Агулам кейс не ўнікальны, таму варта прагугліваць любыя лайфлогінгавыя праграмы, якімі ты карыстаешся. Карпарацыям, натуральна, да ўсяго ёсць справа: і да месячных, і да таго, што мы ямо, ці як вытрачаем грошы.
Хакнутае генеалагічнае дрэва
Магчыма, і ты праходзіў(-ла) генетычны тэст на адным з папулярных сайтаў, каб атрымаць ключ да сваёй гісторыі і ідэнтычнасці. Але ці задумваўся(-лася) ты, наколькі гэта бяспечна? Скандал, што разгарэўся вакол брытанскай кампаніі 23andMe, якая зрабіла ДНК-тэсты папулярнымі сярод мільёнаў людзей і праклала сцежку ў гэтым кірунку іншым, мусіць як мінімум насцярожваць.
Цяпер піянер аматарскай генеалогіі праходзіць працэдуру банкруцтва, хоць на піку папулярнасці кошт 23andMe ацэньваўся ў 6 млрд даляраў, а да раскруткі кампаніі прыклалі руку зоркі першай велічыні: Опра Ўінфры, Снуп Дог і Ева Лангорыя. Як бы там ні было, але 23andMe так і не змагла знайсці ўстойлівую мадэль развіцця, бо пасля атрымання ДНК-справаздачы дыялог з карыстальнікамі заканчваўся, ёй не было чаго прапанаваць у дадатак. Але нас найперш цікавяць не магчымыя спосабы манетызацыі такіх стартапаў, а тое, як надзейна захоўваюцца вельмі чуллівыя дадзеныя іх юзераў.
Яшчэ ў 2023 годзе дадзеныя мільёнаў кліентаў 23andMe былі злітыя падчас хакерскай атакі. У базе засвяціліся і 50 грамадзян Беларусі, якія даслалі сваю сліну на «расшыфроўку» ДНК. У рукі хакераў дакладна трапіла інфармацыя пра даты нараджэння людзей, іх месцазнаходжанне і генеалагічнае дрэва. Як сцвярджала тады кампанія, уласна ДНК-тэсты скрадзеныя не былі, але ў гэтай гісторыі засталося шмат белых плямаў.
Агульныя высновы: калі нешта ёсць у інтэрнэце – яно можа аказацца недзе яшчэ. Але варта прынамсі рэгуляваць ці дазаваць аб’ёмы выкладзенай «чорнаму люстэрку» інфармацыі, час ад часу чэкаць налады канфідэнцыяльнасці ў апках і не ігнараваць дамаўленні пра збор дадзеных (хоць, вядома, хто чытае той дробны шрыфт?).
Фота: Her / 2013